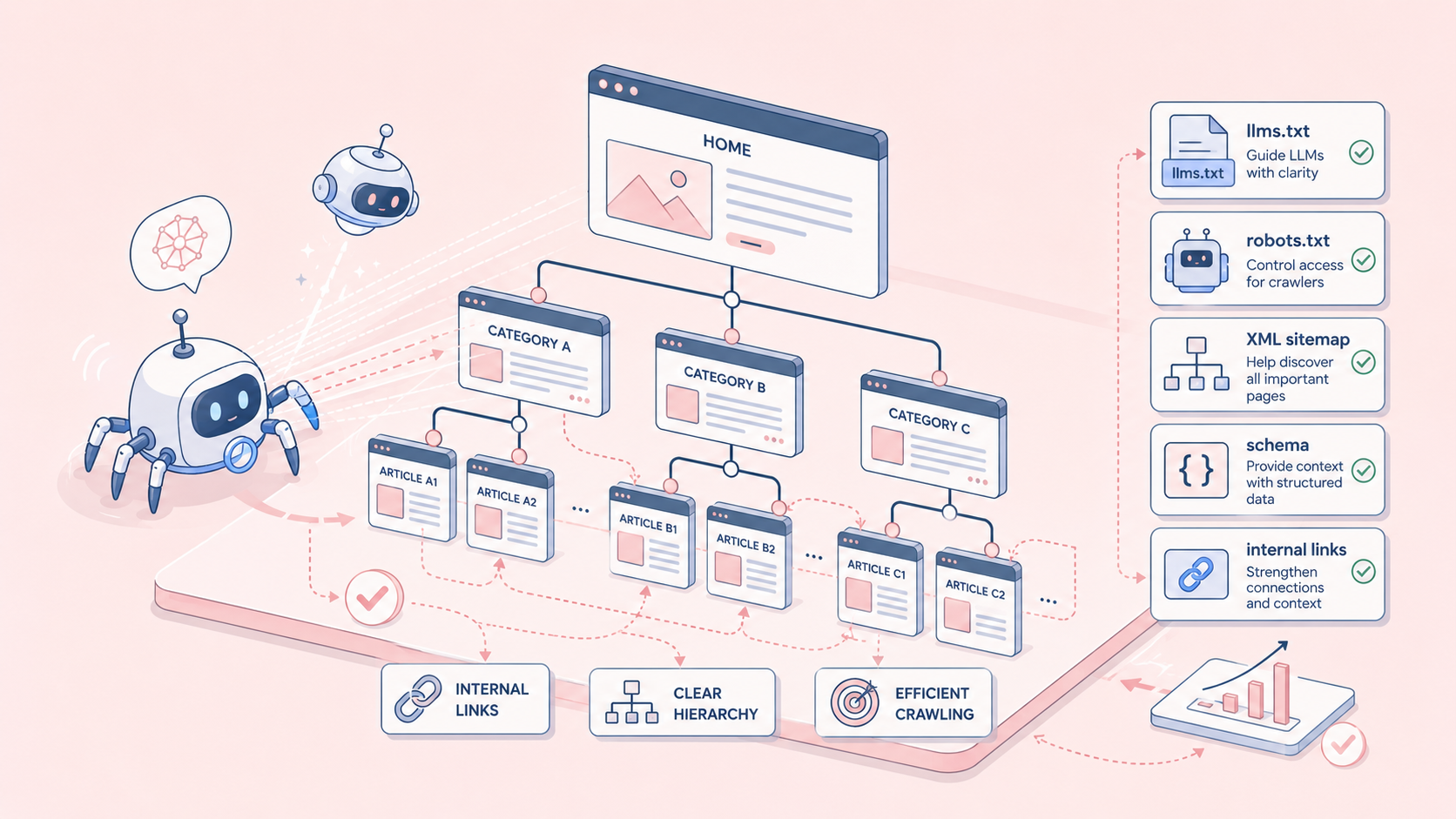
近年、AI技術の進化は目覚ましく、検索エンジンの世界にも大きな変革をもたらしています。特に、LLM(大規模言語モデル)を搭載したAIクローラーの登場は、WebサイトのSEO戦略を再考するきっかけとなっています。従来のGooglebotとは異なる動きをするLLMクローラーは、コンテンツの「意味」をより深く理解しようと努め、AI検索結果やLLMの学習データに大きな影響を与える可能性があります。
しかし、「LLM クローラー 対応」と聞いても、具体的に何をすれば良いのか、従来のSEOと何が違うのか、疑問に感じる方も少なくないでしょう。サイト構造やコンテンツ、技術的な側面まで、多岐にわたる最適化が求められる時代です。この変化に適応できなければ、せっかくの高品質な情報もAIの目に留まらず、機会損失につながりかねません。
この記事では、LLMクローラーに最適化されたWebサイト構造を構築するための具体的な方法を、SEOの専門的な知見に基づいて徹底解説します。クローリング効率の向上からインデックス最適化、レンダリング対策、さらにはGoogle Discoverでの露出最大化まで、多角的なアプローチで貴社のサイトを次世代の検索環境に対応させましょう。まずはご自身のサイトがLLMクローラーにどれだけ対応できているか、無料サイト診断で確認してみるのも良いでしょう。
この記事でわかること
- LLMクローラーの仕組みと従来のクローラーとの違い
- クローリング効率を最大化するサイト構造の設計方法
- コンテンツのインデックス最適化とLLMによる意味理解の促進
- Core Web Vitalsとレンダリング対策の重要性
- モバイルフレンドリーとGoogle Discoverへの対応戦略
- LLM時代におけるrobots.txtとHTML構文のベストプラクティス
LLMクローラーとは?その特徴とSEOへの影響
LLMクローラーとは、Googlebotのような従来の検索エンジンクローラーとは異なり、大規模言語モデル(LLM)の能力を活用してWebページを巡回し、その内容を深く理解しようとする新しいタイプのボットです。代表的なものとしては、OpenAIのGPTBotやAnthropicのClaudeBotなどが挙げられます。これらのクローラーは、単にHTML構造を解析するだけでなく、テキストの文脈、意味、意図までを把握し、コンテンツの質や関連性をより高度に評価する能力を持っています。
従来のクローラーが主にキーワードやリンク構造、HTMLタグといったシグナルを基にページを評価していたのに対し、LLMクローラーは自然言語処理の進化により、あたかも人間が読解するようにコンテンツを解釈します。これにより、単語の羅列ではない、真に価値のある情報が埋もれることなく評価される可能性が高まります。たとえば、あるトピックについて専門的な知識が体系的にまとめられているページは、関連キーワードが散りばめられているだけのページよりも、LLMクローラーにとって価値が高いと判断される傾向にあります。これは、検索エンジンがユーザーの質問に対してより正確で質の高い回答を提供しようとする動きと軌を一にするものです。
(回答準備中)
LLMクローラーへの対応は、AI検索の結果に直接影響を与えるだけでなく、将来的なLLMの学習データとして自社情報が採用される機会を確保することにもつながります。AIアシスタントやチャットボットが情報を生成する際、信頼できるWebサイトからの引用は不可欠です。もし貴社のサイトがLLMクローラーに適切にクロールされ、その内容が正確に理解されれば、AIが生成する回答に貴社の情報が引用される可能性が高まります。これは、新たな形の露出機会であり、ブランド認知の向上にも寄与するでしょう。反対に、LLMクローラーをブロックしてしまうと、AI検索での露出機会が減少し、情報が拡散されにくくなるリスクがあります。現時点では、特に中小企業サイトにおいては、LLMクローラーをブロックしないことをGoogleも推奨しています。
この新しい時代のクローラーに対応するためには、単なるキーワード最適化に留まらず、コンテンツの質、情報の網羅性、そしてユーザーにとっての読みやすさを徹底的に追求することが重要です。また、技術的な側面から見ても、クローラーがサイトを効率的に巡回し、誤解なく情報を取得できるような構造を整える必要があります。具体的には、サイトの表示速度、モバイル対応、そしてHTML構文の正確性など、基本的なSEO要素がこれまで以上に重要性を増しています。これらの要素は、人間ユーザーだけでなく、LLMクローラーにとっても「良いサイト」であるための共通基盤となるのです。私たちは多くのクライアント様との議論を通じて、このような基礎的な部分の徹底が、最終的に大きな成果に繋がることを再認識しています。
LLMクローラーは、Webサイトが提供する情報の「本質的な価値」を見抜く目を持ち合わせています。したがって、表面的なテクニックに頼るのではなく、ユーザーに真に役立つコンテンツを提供することに焦点を当てることが、結果的にLLMクローラーへの最適化へとつながるでしょう。これは、SEOの本質が「ユーザーファースト」であることを改めて示すものと言えます。
クローリング効率を最大化するサイト構造の基本
Webサイトのクローリング効率を最大化することは、LLMクローラーを含むあらゆる検索エンジンクローラーにとって非常に重要です。効率的なクローリングがなければ、せっかくの高品質なコンテンツも発見されにくくなり、インデックスされずに終わってしまう可能性があります。サイト構造の最適化は、クローラーが迷うことなく、効率的にサイト内のすべての重要なページに到達できるようにするための道筋を作る作業に例えられます。まるで地図と標識を整備するようなものです。
まず、**URL構造のシンプル化と一貫性**は基本中の基本です。短く、わかりやすく、キーワードを含むURLは、ユーザーにとってもクローラーにとっても理解しやすいものです。例えば、「https://example.com/category/product-name/」のように階層が明確なURLは、ページのテーマを推測しやすく、サイト全体の構造をクローラーに伝える上で役立ちます。動的なパラメータが多すぎるURLや、意味不明な文字列の羅列は避けるべきでしょう。これは、LLMがURLからもコンテンツの関連性を推測する可能性があるため、より一層重要性を増しています。
次に、**内部リンクの最適化**が挙げられます。サイト内のページ同士を適切にリンクで繋ぐことで、クローラーは関連性の高いページを発見しやすくなります。重要なページには、サイト内の様々な場所から適切なアンカーテキストでリンクを張ることが推奨されます。特に、パンくずリストや関連コンテンツへのリンクは、クローラーの巡回を助けるだけでなく、ユーザーの利便性も高めます。例えば、ブログ記事の末尾に「この記事を読んだ方におすすめ」といった形で関連記事へのリンクを設置することは、ユーザーの滞在時間を延ばし、クローラーにもサイトの深さを伝える効果があります。
さらに、**XMLサイトマップの活用**は、クローリング効率を高める上で欠かせません。Google Search Centralのガイドラインでも推奨されているように、XMLサイトマップは、サイト内のすべての重要なページのURLを検索エンジンに伝えるための「地図」の役割を果たします。特に新規ページや更新頻度の低いページは、サイトマップに含めてGoogle Search Consoleに送信することで、発見を促進できます(Google Search Central「サイトマップについて」参照)。また、画像コンテンツが多いサイトでは、既存のXMLサイトマップに`
そして、**HTTPS化の徹底**も忘れてはなりません。Googleは2014年からHTTPSをランキングシグナルに使用すると発表しており(Google「HTTPSをランキングシグナルに使用」参照)、セキュリティ向上だけでなく、微小ながらも検索順位に良い影響を与えます。LLMクローラーも安全なサイトを優先する傾向にあるため、サイト全体をHTTPS化し、混在コンテンツ(HTTP読み込み)を排除することが必須です。私たちの経験上、HTTPS化されていないサイトでは、信頼性の面で不利になるケースを多く見てきました。これは、ユーザー体験だけでなく、クローラーにとっても重要な「信頼性」の指標となるため、徹底して対応すべきポイントです。
これらの基本的なサイト構造の最適化は、LLMクローラーが貴社のサイトを「効率的」かつ「正確」に理解するための土台となります。単なる技術的な側面だけでなく、ユーザーが情報を探しやすく、快適に利用できる構造を追求することが、結果的にクローラーフレンドリーなサイトへとつながるのです。
インデックス最適化とLLMの理解を深めるコンテンツ戦略
LLMクローラーに対応したサイト構造を構築する上で、クローリング効率と並んで重要なのが、コンテンツのインデックス最適化とLLMによる意味理解を促進するための戦略です。クローラーがサイトを巡回しても、コンテンツの内容が適切にインデックスされ、LLMに正しく理解されなければ、検索結果での露出やAIからの引用にはつながりません。コンテンツはWebサイトの「魂」とも言える部分であり、ここでの最適化がLLM時代のSEO成功の鍵を握ると言っても過言ではないでしょう。
まず、**高品質で網羅性の高いコンテンツの提供**が最優先事項です。LLMクローラーは、特定のトピックについて深く掘り下げられ、ユーザーの疑問を完全に解消できるようなコンテンツを高く評価します。単にキーワードを詰め込むのではなく、関連するサブトピックやFAQ、専門用語の解説などを盛り込み、読者が求める情報を一箇所で完結できるような記事を目指しましょう。例えば、ある製品の紹介記事であれば、その機能、メリット、デメリット、使い方、競合との比較、利用者の声、よくある質問といった要素を網羅することで、LLMはコンテンツの「専門性」と「網羅性」をより深く理解できるようになります。これは、読者にとっても非常に価値のある情報源となるため、自然とエンゲージメントも高まるはずです。
次に、**構造化データの活用**は、LLMがコンテンツの意味を正確に理解するための強力な手助けとなります。構造化データ(Schema.org)をHTMLにマークアップすることで、検索エンジンはページの内容をより明確に把握できるようになります。例えば、商品ページであれば価格、在庫状況、レビュー評価を、イベントページであれば日時、場所、出演者情報を、レシピページであれば材料、調理時間、手順を明示的に伝えることができます。これにより、LLMは「これはレシピのページであり、材料は〇〇で、調理時間は△△だ」といった具体的な情報を迷いなく抽出できるようになります。これは、AIが生成する回答に貴社の情報が引用される際にも、その正確性を担保する上で非常に有効な手段と言えるでしょう。
さらに、**検索意図への合致**は、LLM時代においても変わらず重要です。ユーザーがどのような情報を求めて検索しているのかを深く理解し、その意図に沿ったコンテンツを提供することが、LLMによる評価を高めます。例えば、「LLM クローラー 対応」というキーワードで検索するユーザーは、その定義だけでなく、具体的な対策方法やメリット・デメリット、今後の展望まで知りたいと考えているかもしれません。単一のキーワードだけでなく、関連キーワードやサジェストキーワードを分析し、ユーザーの潜在的な疑問まで先回りして解決するようなコンテンツを作成することで、LLMはそのコンテンツがユーザーにとって非常に有用であると判断するでしょう。私たちは、クライアント様のサイト分析において、ユーザーの離脱タイミングを捉え、その裏にある真の検索意図を深掘りすることで、リード獲得に繋がるコンテンツ改善提案を行ってきました。単なるPV増だけでなく、ビジネス成果に直結するコンテンツ作りが求められます。
また、コンテンツの更新頻度もLLMクローラーにとって重要なシグナルとなり得ます。フレッシュな情報は、LLMが最新の動向を学習し、AI検索で正確な情報を提供する上で欠かせません。既存のコンテンツも定期的に見直し、最新情報に更新することで、その価値を維持・向上させることが可能です。これは、Google Discover最適化の観点でも「フレッシュネス」が重要な要因とされていることからも、その重要性が伺えます(Google Discover SDKの解析結果、Faber Company紹介、2026-02)。古い情報が放置されているサイトは、LLMから「信頼性の低い情報源」と判断されるリスクもあるため、常に鮮度を保つ意識が大切です。
LLMクローラーは、コンテンツの「質」と「意味」を深く評価します。キーワードを機械的に配置するのではなく、ユーザーにとって本当に価値のある情報を提供し、それを構造化データで明確に伝えることが、インデックス最適化とLLMによる理解を深めるための最善策となるのです。このアプローチは、結果的に人間ユーザーの満足度を高め、検索エンジンからの評価も向上させるという、理想的なサイクルを生み出します。
レンダリング対策とCore Web Vitalsの重要性

LLMクローラーがWebサイトのコンテンツを正確に理解するためには、サイトが適切に「レンダリング」されることが前提となります。レンダリングとは、HTML、CSS、JavaScriptなどのコードをブラウザが解釈し、最終的にユーザーが見る視覚的なページを生成するプロセスです。特にJavaScriptを多用する現代のWebサイトでは、このレンダリングのプロセスが複雑になりがちで、クローラーが完全にページを読み込めない、あるいは表示に時間がかかりすぎるという課題が生じることがあります。LLMクローラーもこのレンダリングの結果に基づいてコンテンツを理解しようとするため、レンダリング対策はSEOにおいて非常に重要な要素となります。
JavaScriptレンダリングの課題に対処するためには、まず**サーバーサイドレンダリング(SSR)や静的サイトジェネレーター(SSG)の導入**を検討することが有効です。これにより、ブラウザ側でJavaScriptが実行される前に、サーバー側でHTMLが生成されるため、クローラーはより早く、完全にレンダリングされたコンテンツにアクセスできます。もちろん、全てのサイトでSSRやSSGが最適なわけではありませんが、SPA(シングルページアプリケーション)などでJavaScriptに大きく依存している場合は、このアプローチがクローリングとインデックスの効率を大きく改善する可能性があります。
そして、レンダリング対策と密接に関連するのが、**Core Web Vitalsの最適化**です。GoogleはCore Web Vitalsを「ページエクスペリエンスシグナル」の一部としてランキング要因に採用しており、ユーザー体験の向上だけでなく、検索順位にも正の影響を与えると明言しています(Google「ページエクスペリエンスシグナル」参照)。LLMクローラーもユーザー体験の良いサイトを優先的に評価する傾向にあるため、Core Web Vitalsの改善は間接的にLLM対応にもつながります。
- LCP(Largest Contentful Paint): 最大コンテンツの描画時間
ページのメインコンテンツが読み込まれるまでの時間で、目標値は2.5秒以内です。LCPを改善するには、画像の最適化(圧縮、次世代フォーマットへの変換)、サーバー応答時間の改善(CDNの導入、サーバーの高速化)、レンダリングブロックするCSSやJavaScriptの削減が有効です。ユーザーが最初に目にする情報が素早く表示されることは、サイトへの信頼感を高める上で非常に重要です。 - INP(Interaction to Next Paint): インタラクション遅延
ユーザーがページを操作(クリック、タップなど)してから、その操作に対する視覚的な反応が描画されるまでの遅延時間を示し、目標値は200ms以内です。INPの改善には、JavaScriptの実行時間を短縮し、メインスレッドのブロックを避けることが不可欠です。不要なJavaScriptの削除、遅延読み込み(defer/async)、Web Workersの活用などが挙げられます。ユーザーがスムーズに操作できるサイトは、離脱率の低下にもつながります。 - CLS(Cumulative Layout Shift): レイアウトシフト
ページの読み込み中に予期せずレイアウトがずれる現象の度合いで、目標値は0.1以内です。CLSを改善するには、画像や動画のサイズをHTMLで明示的に指定する、Webフォントの読み込みを最適化する、動的に挿入されるコンテンツのスペースを確保するといった対策が有効です。予期せぬレイアウトのずれはユーザーに不快感を与え、誤クリックの原因にもなるため、LLMクローラーもこれをネガティブな要素として認識する可能性があります。
これらのCore Web Vitalsの指標は、Google Search Consoleの「Core Web Vitals」レポートで確認できます。定期的にサイトのパフォーマンスを監視し、継続的に改善していくことが、LLMクローラー時代におけるSEOの生命線となるでしょう。データに基づいた継続的なアプローチは、単なる実装完了ではなく、ユーザー体験と検索エンジンからの評価を向上させ、成果に直結することを私たちは数多くのプロジェクトで実感しています。
レンダリングとCore Web Vitalsの最適化は、技術的な側面が強いですが、最終的にはユーザーに快適な体験を提供し、LLMクローラーが貴社のコンテンツをスムーズに理解するための基盤を築くことにつながります。これは、まるで建物の基礎工事のようなもので、目には見えにくい部分ですが、その後の構造全体の安定性や耐久性を決定づける重要な工程なのです。
モバイルフレンドリーとDiscover最適化で露出を増やす

LLMクローラーへの対応を考える上で、モバイルフレンドリーとGoogle Discover最適化は、サイトの露出を最大化し、より多くのユーザーに情報を届けるための重要な戦略です。現代において、多くのユーザーがスマートフォンからインターネットにアクセスしていることを踏まえれば、これらの要素はもはや「あれば良い」ものではなく、「必須」の要件と言えるでしょう。
まず、**モバイルフレンドリー**は、Googleが「モバイルファーストインデックス」を導入して以来、SEOの根幹をなす要素となっています(Google「モバイルサイトとモバイルファーストインデックス」参照)。これは、Googleがモバイル版のコンテンツを主に評価してランキングを決定するという方針です。したがって、PCサイトだけでなく、モバイルデバイスでも快適に閲覧できるレスポンシブデザインの実装が不可欠です。具体的には、``をHTMLの`
`内に記述し、CSSでビューポートのサイズに応じてレイアウトが最適化されるように調整します。モバイルユーザビリティはGoogle Search Consoleで確認できるため、定期的にチェックし、改善を続けることが重要です。LLMクローラーも、モバイルユーザーにとって使いやすいサイトの情報を優先的に学習し、AI検索結果に反映させる可能性が高いと考えられます。次に、**Google Discover最適化**は、特にニュースサイトやメディア、ブログなど、コンテンツの鮮度が重要なサイトにとって、大量のトラフィックを獲得する大きなチャンスとなります。Google Discoverは、ユーザーの興味や過去の閲覧履歴に基づいてパーソナライズされたコンテンツを表示するフィードサービスであり、ここに表示されることで予期せぬほどのトラフィック流入が見込めます。Google Discover SDKの解析結果(Faber Company紹介、2026-02)によると、Discoverでの露出を最大化するためには以下の5つのランキング要因への対応が鍵となります。
- OGタグ(Open Graph Protocol): 特に`og:image`(1200×630px推奨)と`og:title`を全ページに設定することが重要です。魅力的で高品質なアイキャッチ画像と、クリックされやすいタイトルは、Discoverフィードでの「予測CTR」を高める上で不可欠です。私たちは、ニュースサイトのクライアント様でOGタグ設定状況を重点的にチェックし、画像サイズ不足などの改善提案を行うことで、Discoverからのトラフィックが大幅に増加した事例を目の当たりにしました。
- 予測CTR(Click Through Rate): ユーザーがフィード上でクリックしたくなるようなタイトルやアイキャッチ画像の最適化が求められます。これは、コンテンツの魅力を最大限に引き出すためのコピーライティングやビジュアルデザインの工夫に直結します。
- フレッシュネス: コンテンツ公開後7日間が最も重要とされています。鮮度が落ちると表示されなくなるため、常に新しい情報を提供したり、既存記事を最新情報に更新したりすることが大切です。記事公開日(`datePublished`)と更新日(`dateModified`)を正しく設定し、定期的に更新しましょう。
- パーソナライズ: ユーザーの過去の閲覧行動に基づいて表示されるため、直接制御は困難ですが、幅広い興味関心に対応できる多様なコンテンツを提供することが間接的な対策となります。
- ネガティブフィードバック: ユーザーが「興味なし」ボタンを押した場合に減点される要因です。コンテンツの品質を高く保ち、ユーザーの期待を裏切らないことが重要です。
さらに、Discoverで大きな画像プレビューを表示させるために、``のメタタグを設定することも推奨されます。これにより、より視覚的に魅力的な形でコンテンツがDiscoverフィードに表示され、ユーザーの目を引く可能性が高まります。
モバイルフレンドリーとDiscover最適化は、それぞれ異なるアプローチですが、共通して「ユーザー体験の向上」と「コンテンツの魅力的な提示」を目指すものです。LLMクローラーも、これらの最適化を通じて、サイトがユーザーにとってどれだけ価値のある情報を提供しているかを評価するでしょう。まるで、お店の入り口をきれいに整え、魅力的な商品をわかりやすく並べるようなものです。これにより、より多くの人々がお店に立ち寄り、商品に興味を持つきっかけが生まれるのです。
LLMクローラー時代のrobots.txtとHTML構文の重要性
LLMクローラーに対応したサイト構造を維持する上で、`robots.txt`によるアクセス管理とHTML構文の正確性は、見過ごされがちなものの極めて重要な技術的側面です。これらはクローラーがサイトをどのように巡回し、情報をどのように解釈するかを直接的に左右するため、適切に設定・管理することが求められます。特に、LLMクローラーは従来のGooglebotとは異なる目的を持つ場合があるため、その違いを理解し、戦略的に対応することが肝要です。
まず、**`robots.txt`によるLLMクローラーのアクセス管理**についてです。`robots.txt`は、検索エンジンクローラーに対してサイト内のどのURLにアクセスして良いか、あるいはアクセスしてはいけないかを指示するファイルです。LLMクローラーの中には、OpenAIのGPTBotやAnthropicのClaudeBotのように、独自のUser-agentを持つものが存在します(OpenAI GPTBot仕様参照)。これらのクローラーに対して、自社のコンテンツをAIの学習データとして利用させたいか、AI検索での引用を許可したいかによって、`robots.txt`の設定を調整する必要があります。
| 判断 | 設定 |
|---|---|
| AI引用されたい | Allow: / |
| 学習に使われたくない | Disallow: / |
| 部分的に許可 | ページ単位で制御 |
具体的には、`robots.txt`に以下のような記述を追加することで、各LLMクローラーのアクセスを制御できます。
# robots.txt での制御例
User-agent: GPTBot
Allow: /
User-agent: ClaudeBot
Allow: /
User-agent: Google-Extended
Allow: /ここで注目すべきは「Google-Extended」です。これはGoogleのAI学習用クローラーであり、従来のGooglebotとは別の目的でサイトを巡回します。もしAI検索での露出やLLMの学習データへの自社情報反映を望むのであれば、これらのクローラーをブロックしないことを推奨します。鈴木健一氏も「クローラーに優しいサイトはGoogleにもLLMにも有効」と指摘しているように、闇雲にブロックするのではなく、戦略的にアクセスを許可することが、LLM時代における新たな機会創出につながります。ただし、特定のコンテンツをAI学習から除外したい場合は、ページ単位で`Disallow`を設定することも可能です。これはまるで、家の玄関に「ここは入ってOK、あそこは立ち入り禁止」と札を立てるようなものです。
次に、**HTML構文の正確性**は、LLMクローラーがコンテンツを正しく理解し、SEOシグナルを正確に伝達するために不可欠です。Gary Illyes氏(Google)がSearch Off The Record ポッドキャスト(2026-03-08、ねぎお社長SEOウィークリーで紹介)で言及したように、崩れたHTMLはブラウザが自動補正して表示するものの、Googlebotは`hreflang`、`canonical`、`head`内のタグといったSEOシグナルを正しく読み取れなくなる可能性があります。LLMクローラーも、HTMLの構造的な正確性からコンテンツの信頼性を判断する可能性があるため、構文エラーは避けるべきです。
| HTMLエラー | SEOへの影響 |
|---|---|
<head>内の閉じタグ欠落 | meta/link要素がbody扱いになりシグナル喪失 |
| hreflangの記述ミス | 多言語対応が機能しない |
| canonicalタグの構文エラー | URL正規化が無効になり重複扱い |
| meta/linkタグの順序・ネスト誤り | 後続タグが無視される可能性 |
これらのリスクを回避するためには、W3C Markup Validation ServiceのようなツールでHTML構文を定期的に検証し、エラーを修正することが重要です。また、ブラウザのDevToolsの「Elements」パネルで表示上のDOMと実際のソースHTMLの差異を確認することも有効です。もし差異がある場合、ブラウザが自動補正している可能性が高く、Googlebotが正しく読み取れていないサインかもしれません。これは、プログラミング言語における文法ミスのようなもので、小さなミスが全体に大きな影響を与えることがあります。
LLMクローラーは、より高度な方法でWebを理解しようとしていますが、その基盤には正確でクリーンな技術的要素が不可欠です。`robots.txt`で意図を明確に伝え、正確なHTML構文でコンテンツの構造を提示することで、LLMクローラーは貴社のサイトを最大限に評価し、AI検索や学習データへの貢献を促進するでしょう。これは、技術SEOの基本でありながら、LLM時代にその重要性が再認識されている領域と言えます。もしサイト構造の最適化について専門的なアドバイスが必要でしたら、ぜひ無料ウェブ面談をご活用ください。
FAQ: LLMクローラー対応に関するよくある質問
Q1: LLMクローラーをブロックすると、Google検索の順位に悪影響がありますか?
LLMクローラー(GPTBot, ClaudeBotなど)をブロックしても、直接的にGoogle検索の順位に悪影響を与えることは現時点ではありません。Googlebot(従来の検索エンジンクローラー)とLLMクローラーは異なる目的でサイトを巡回しており、それぞれ独立して機能しているためです。しかし、間接的な影響は考えられます。LLMクローラーをブロックすると、AI検索結果での貴社コンテンツの引用機会が失われたり、LLMの学習データとして利用されなくなるため、長期的に見ると、AI関連の露出機会が減少し、ブランド認知やトラフィック獲得のチャンスを逃す可能性があります。特に中小企業サイトでは、ブロックせずに情報を開示することを推奨します。
Q2: どのようなコンテンツがLLMクローラーに評価されやすいですか?
LLMクローラーは、単なるキーワードの羅列ではなく、コンテンツの「意味」や「文脈」を深く理解しようとします。そのため、以下の特徴を持つコンテンツが評価されやすい傾向にあります。
- 網羅性と専門性: 特定のトピックについて深く掘り下げ、ユーザーの疑問を完全に解消できるような、信頼性の高い情報が体系的にまとめられているコンテンツ。
- 明確な構造: Hタグを適切に使用し、段落分けやリスト、表などで情報が整理されているコンテンツ。
- 正確性と最新性: 常に最新の情報に更新され、誤りのない正確なデータに基づいているコンテンツ。
- 構造化データの活用: Schema.orgなどの構造化データをマークアップすることで、コンテンツの意味を明確にクローラーに伝えることができます。
- 自然な言葉遣い: 人間が読んで理解しやすい、自然で流暢な文章が好まれます。
要するに、ユーザーにとって本当に価値があり、読みやすいコンテンツが、LLMクローラーにとっても評価されやすいと言えます。
Q3: Core Web Vitalsの改善は、LLMクローラー対応にどう影響しますか?
Core Web Vitals(LCP, INP, CLS)の改善は、LLMクローラー対応において非常に重要な要素です。GoogleはCore Web Vitalsをランキングシグナルとして使用しており、ユーザー体験の良いサイトを高く評価します。LLMクローラーも、ユーザー体験が悪いサイト(表示が遅い、操作性が悪い、レイアウトが崩れるなど)の情報を優先的に学習したり、AI検索で引用したりする可能性は低いと考えられます。高速で安定したページは、クローラーが効率的にコンテンツを読み込み、レンダリングするのを助け、結果としてLLMがコンテンツの内容を正確に理解するための基盤となります。つまり、Core Web Vitalsの最適化は、間接的にLLMクローラーが貴社のサイトを高く評価し、AI検索での露出機会を増やすことにつながるのです。
まとめ: LLM クローラー 対応で次世代の検索に備える
LLM(大規模言語モデル)クローラーの登場は、WebサイトのSEO戦略に新たな視点をもたらしました。従来の検索エンジン最適化の基本原則は依然として重要ですが、LLMクローラーはコンテンツの「意味」や「文脈」をより深く理解しようとする特性を持つため、これまでの表面的な対策だけでは不十分となる可能性があります。本記事では、「LLM クローラー 対応」をキーワードに、次世代の検索環境で優位に立つためのサイト構造最適化について解説してきました。
クローリング効率を最大化するためには、シンプルで一貫性のあるURL構造、適切な内部リンク、そしてXMLサイトマップの活用が不可欠です。また、HTTPS化はセキュリティと信頼性の両面で、LLMクローラーを含むあらゆる検索エンジンにとって重要なシグナルとなります。コンテンツのインデックス最適化においては、高品質で網羅性の高い情報提供に加え、構造化データの活用がLLMによる意味理解を促進します。ユーザーの検索意図に深く合致するコンテンツは、LLMクローラーに高く評価されるでしょう。
技術的な側面では、レンダリング対策とCore Web Vitalsの最適化が、LLMクローラーがコンテンツを正確に読み込み、ユーザー体験の良いサイトとして評価するための基盤となります。LCP、INP、CLSの改善は、表示速度や操作性を向上させ、結果的に検索順位にも良い影響を与えます。さらに、モバイルフレンドリーとGoogle Discover最適化は、サイトの露出機会を大幅に拡大し、より多くのユーザーに貴社の情報を届けるための重要な戦略です。特にOGタグの適切な設定とコンテンツの鮮度は、Discoverからのトラフィック獲得に直結します。
そして、LLMクローラー時代における`robots.txt`による戦略的なアクセス管理と、HTML構文の正確性は、技術SEOの基本でありながら、その重要性が再認識されています。W3CバリデーターやブラウザのDevToolsを活用し、サイトの技術的な健全性を常に保つことが、LLMによる評価を高める上での隠れた要石となります。私たちは、データに基づいた継続的な改善が、単なる技術的な対応に留まらず、ビジネス成果に直結することを多くのクライアント様との取り組みで実感しています。
LLMクローラーに対応したサイト構造の最適化は、一朝一夕で完了するものではありません。しかし、ユーザーファーストの視点を持ち、本記事で紹介した多角的なアプローチを継続的に実施することで、貴社のWebサイトは次世代の検索環境において、より強力な存在感を放つことができるでしょう。この変化の波をチャンスと捉え、貴社のデジタル戦略を次のレベルへと引き上げましょう。
サイト改善、何から始めればいいかお悩みですか?
シンギDXでは、30分の無料ウェブ面談で貴社サイトの課題を一緒に整理します。改善の優先順位や具体的な施策を、専門家がわかりやすくご説明します。
「まずはセルフチェックから始めたい方は、無料のサイト診断ツールをお試しください。」無料サイト診断を試す




